library("nfidd")
library("dplyr")
library("tidyr")
library("ggplot2")
library("tidybayes")
library("scoringutils")Forecasting models
Introduction
We can classify models along a spectrum by how much they include an understanding of underlying processes, or mechanisms; or whether they emphasise drawing from the data using a statistical approach. In this session, we’ll start with the renewal model that we’ve been using and explore adding both more mechanistic structure and then more statistical structure to the model. We’ll again evaluate these models to see what effect these different approaches might have.
Slides
Objectives
The aim of this session is to introduce some common forecasting models and to evaluate them.
Caution
None of the models introduced in this section are designed for real-world use!
NoteSetup
Source file
The source file of this session is located at sessions/forecasting-models.qmd.
Libraries used
In this session we will use the nfidd package to load a data set of infection times and access stan models and helper functions, the dplyr and tidyr packages for data wrangling, ggplot2 library for plotting, the tidybayes package for extracting results of the inference and the scoringutils package for evaluating forecasts.
Tip
The best way to interact with the material is via the Visual Editor of RStudio.
Initialisation
We set a random seed for reproducibility. Setting this ensures that you should get exactly the same results on your computer as we do. We also set an option that makes cmdstanr show line numbers when printing model code. This is not strictly necessary but will help us talk about the models.
set.seed(123)
options(cmdstanr_print_line_numbers = TRUE)What did we learn about the random walk model from the forecast evaluation session?
- It was unbiased when the reproduction number was approximately constant but when the reproduction number was reducing due to susceptible depletion, the random walk model overestimated the number of cases systematically.
- It did relatively well at short-term forecasting indicating that it was capturing some of the underlying dynamics of the data generating process.
NoteWhat did a geometric random walk model look like again?
R <- geometric_random_walk(init = 1, noise = rnorm(100), std = 0.1)
data <- tibble(t = seq_along(R), R = R)
ggplot(data, aes(x = t, y = R)) +
geom_line() +
labs(title = "Simulated data from a random walk model",
x = "Time",
y = "R")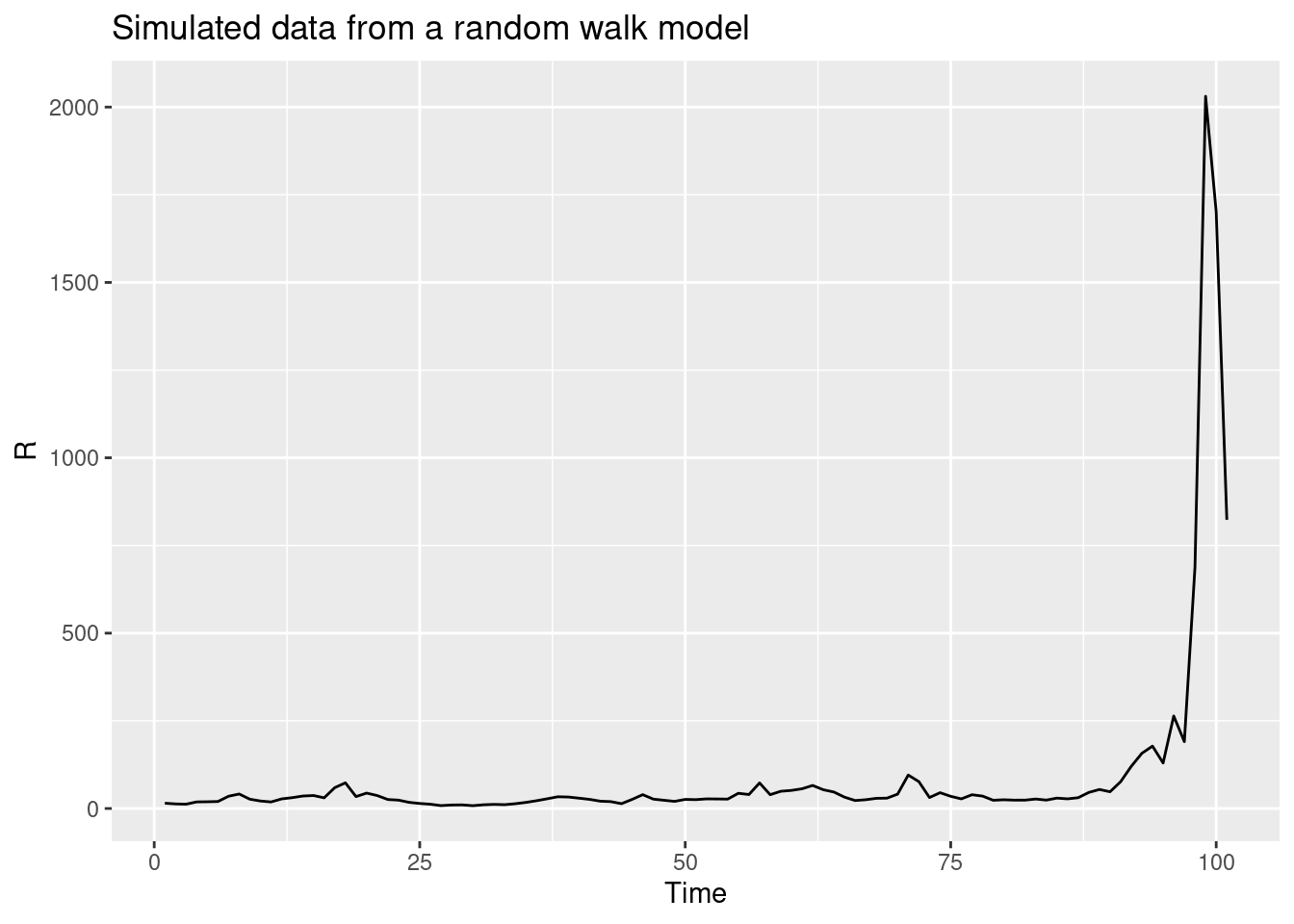
Forecasting models as a spectrum
A large part of this course has been about showing the importance of understanding and modelling the underlying mechanisms of the data generating process. However, in many forecasting scenarios, we may not have a good understanding of the underlying mechanisms, or the data may be too noisy to make accurate predictions. The worst case is that we have mistaken beliefs about the underlying mechanisms and use these to make predictions which are systematically wrong and misleading. In these cases, forecasters often use statistical models to make predictions which have little or no mechanistic basis. In our work, we have found that a combination of mechanistic and statistical models can be very powerful but that identifying the best model for a given forecasting task can be challenging.
Adding more mechanistic structure to the renewal model
One way to potentially improve the renewal model is to add more mechanistic structure. In the forecast evaluation session, we saw that the renewal model was making unbiased forecasts when the reproduction number was constant but that it overestimated the number of cases when the reproduction number was reducing due to susceptible depletion.
Warning
This is slightly cheating as we know the future of this outbreak and so can make a model to match. This is easy to do and important to watch for if wanting to make generalisable methods.
This suggests that we should add a term to the renewal model which captures the depletion of susceptibles. One way to do this is to add a term which is proportional to the number of susceptibles in the population. This is the idea behind the SIR model which is a simple compartmental model of infectious disease transmission. If we assume that susceptible depletion is the only mechanism which is causing the reproduction number to change, we can write the reproduction model as:
\[ R_t = \frac{S_{t-1}}{N} R_0 \]
Note
This approximates susceptible depletion as a linear function of the number of susceptibles in the population. This is a simplification but it is a good starting point.
NoteWhat behaviour would we expect from this model?
n <- 100
N <- 1000
R0 <- 1.5
S <- rep(NA, n)
S[1] <- N
Rt <- rep(NA, n) ## reproduction number
Rt[1] <- R0
I <- rep(NA, n)
I[1] <- 1
for (i in 2:n) {
Rt[i] <- (S[i-1]) / N * R0
I[i] <- I[i-1] * Rt[i]
S[i] <- S[i-1] - I[i]
}
data <- tibble(t = 1:n, Rt = Rt)
ggplot(data, aes(x = t, y = Rt)) +
geom_line() +
labs(title = "Simulated data from an SIR model",
x = "Time",
y = "Rt")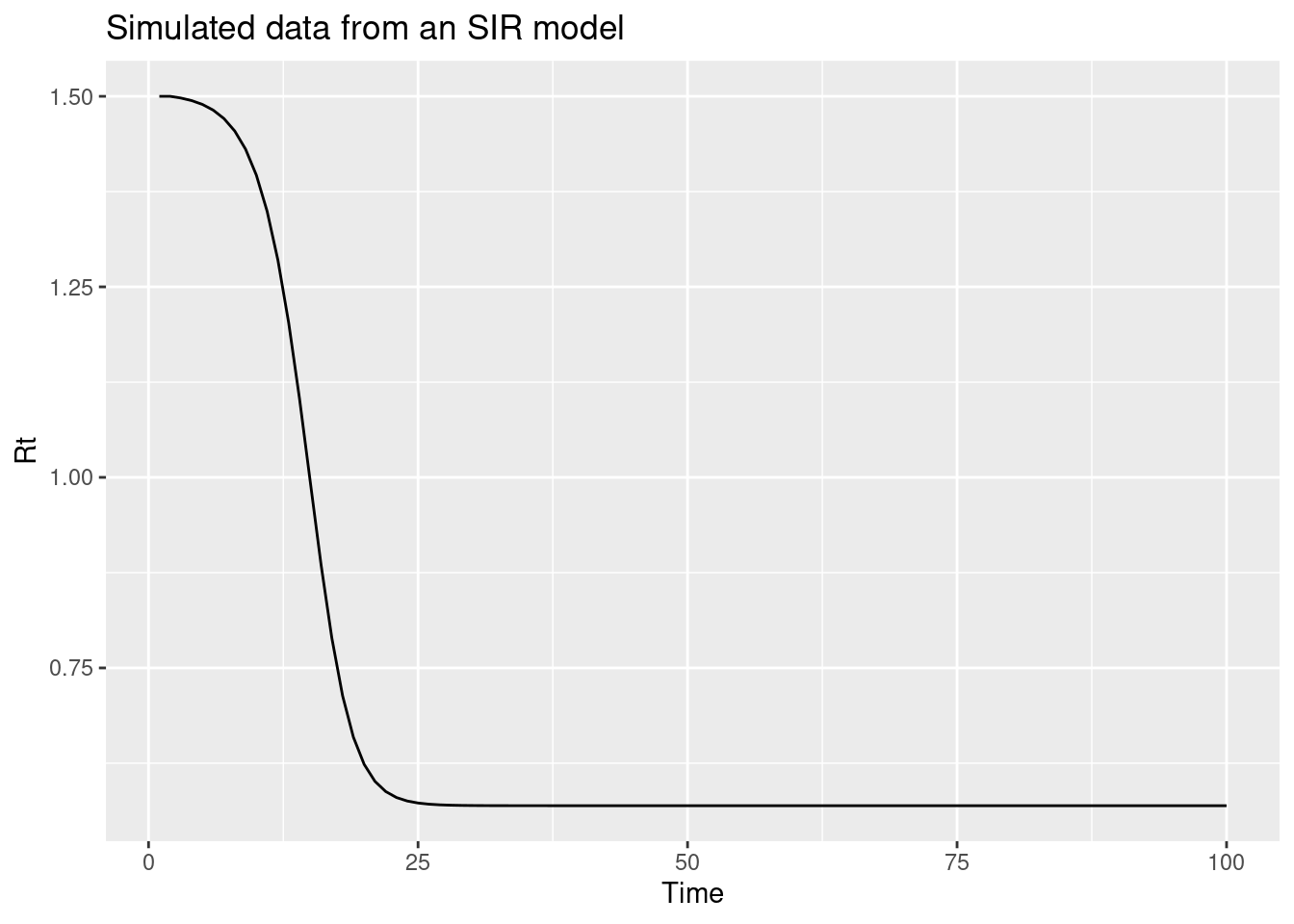
The key assumptions we are making here are:
- The population is constant and we roughly know the size of the population.
- The reproduction number only changes due to susceptible depletion
- The number of new cases at each time is proportional to the number of susceptibles in the population.
We’ve coded this up as a stan model in stan/mechanistic-r.stan. See stan/functions/pop_bounded_renewal.stan for the function which calculates the reproduction number. Let’s load the model:
mech_mod <- nfidd_cmdstan_model("mechanistic-r")
mech_modfunctions {
#include "functions/convolve_with_delay.stan"
#include "functions/pop_bounded_renewal.stan"
}
data {
int n; // number of days
int I0; // number initially infected
array[n] int obs; // observed symptom onsets
int gen_time_max; // maximum generation time
array[gen_time_max] real gen_time_pmf; // pmf of generation time distribution
int<lower = 1> ip_max; // max incubation period
array[ip_max + 1] real ip_pmf;
int h; // number of days to forecast
array[2] real N_prior; // prior for total population
}
transformed data {
int m = n + h;
}
parameters {
real<lower = 0> R; // initial reproduction number
real<lower = 0> N; // total population
}
transformed parameters {
array[m] real infections = pop_bounded_renewal(I0, R, gen_time_pmf, N, m);
array[m] real onsets = convolve_with_delay(infections, ip_pmf);
}
model {
// priors
R ~ normal(1, 0.5) T[0,];
N ~ normal(N_prior[1], N_prior[2]) T[0,];
obs ~ poisson(onsets[1:n]);
}
generated quantities {
array[h] real forecast;
if (h > 0) {
for (i in 1:h) {
forecast[i] = poisson_rng(onsets[n + i]);
}
}
}Adding more statistical structure to the renewal model
Adding more mechanistic structure is not always possible and, if we don’t specify mechanisms correctly, might make forecasts worse. Rather than adding more mechanistic structure to the renewal model, we could add more statistical structure with the aim of improving performance. Before we do this, we need to think about what we want from a forecasting model. As we identified above, we want a model which is unbiased and which has good short-term forecasting properties. We know that we want it to be able to adapt to trends in the reproduction number and that we want it to be able to capture the noise in the data. A statistical term that can be used to describe a time series with a trend is saying that the time series is non-stationary. More specifically, a stationary time series is defined as one whose statistical properties, such as mean and variance, do not change over time. In infectious disease epidemiology, this would only be expected for endemic diseases without external seasonal influence.
The random walk model we used in the forecasting concepts session is a special case of a more general class of models called autoregressive (AR) models. AR models are a class of models which predict the next value in a time series as a linear combination of the previous values in the time series. The random walk model is specifically a special case of an AR(1) model where the next value in the time series is predicted as the previous value, multiplied by a value between 1 and -1 , plus some noise. This becomes a random walk when the multipled value is 0.
For the log-transformed reproduction number (\(log(R_t)\)), the model is:
\[ log(R_t) = \phi log(R_{t-1}) + \epsilon_t \]
where \(\epsilon_t\) is a normally distributed error term with mean 0 and standard deviation \(\sigma\) and \(\phi\) is a parameter between -1 and 1. If we restrict \(\phi\) to be between 0 and 1, we get a model which is biased towards a reproduction number of 1 but which can still capture trends in the data that decay over time.
NoteWhat behaviour would we expect from this model?
n <- 100
phi <- 0.4
sigma <- 0.1
log_R <- rep(NA, n)
log_R[1] <- rnorm(1, 0, sigma)
for (i in 2:n) {
log_R[i] <- phi * log_R[i-1] + rnorm(1, 0, sigma)
}
data <- tibble(t = 1:n, R = exp(log_R))
ggplot(data, aes(x = t, y = R)) +
geom_line() +
labs(title = "Simulated data from an exponentiated AR(1) model",
x = "Time",
y = "R")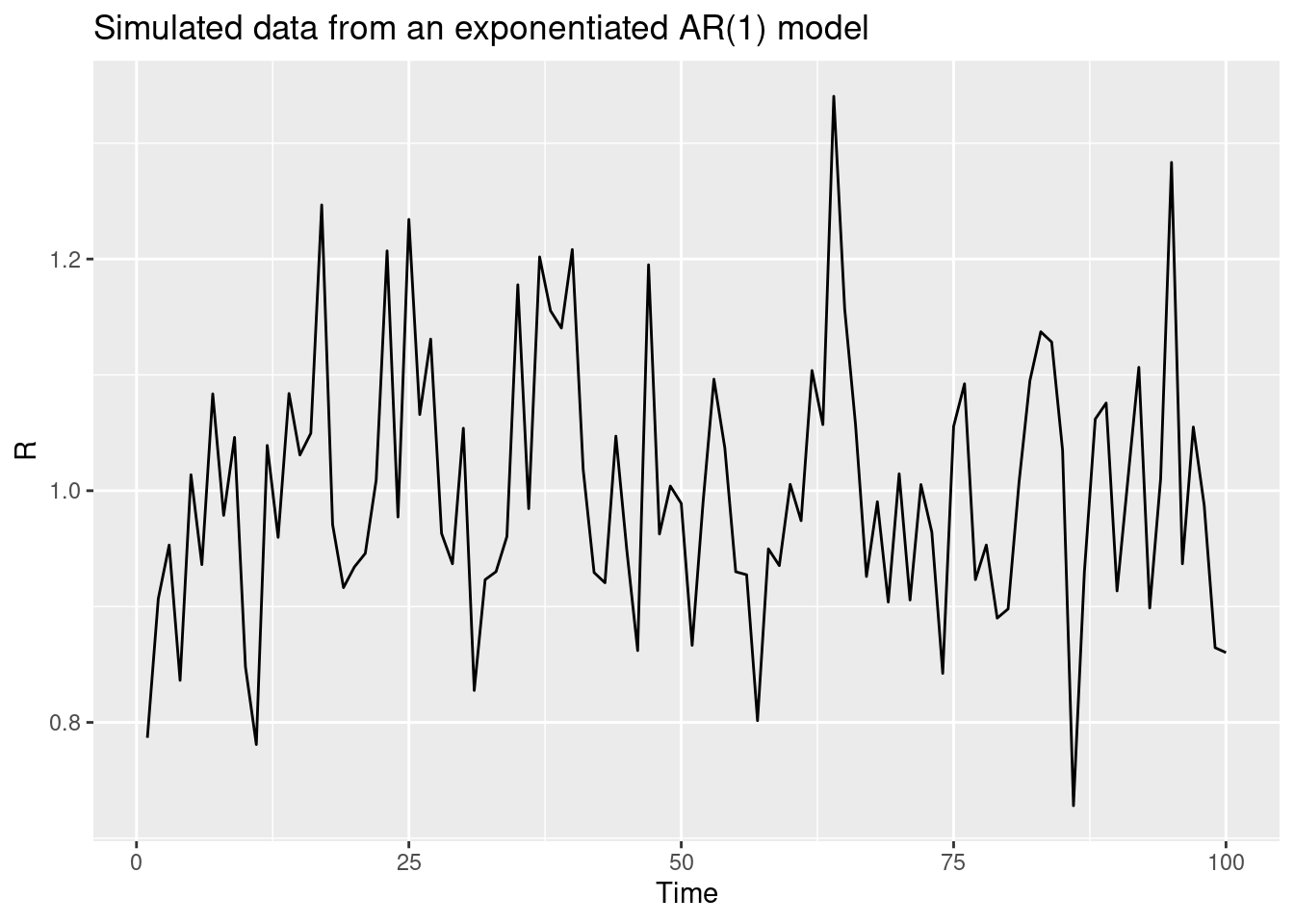
However, we probably don’t want a model which is biased towards a reproduction number of 1 (unless we have good reason to believe that is the expected behaviour). So what should we do?
Returning to the idea that the reproduction number is a non-stationary time series, as we expect to have a trend in the reproduction numbers we want to capture, we can use a method from the field of time series analysis called differencing to make the time series stationary. This involves taking the difference between consecutive values in the time series. For the log-transformed reproduction number, this would be:
\[ log(R_t) - log(R_{t-1}) = \phi (log(R_{t-1}) - log(R_{t-2})) + \epsilon_t \]
NoteWhat behaviour would we expect from this model?
Again we look at an R function that implements this model:
geometric_diff_arfunction (init, noise, std, damp)
{
n <- length(noise) + 1
x <- numeric(n)
x[1] <- log(init)
x[2] <- x[1] + noise[1] * std
for (i in 3:n) {
x[i] <- x[i - 1] + damp * (x[i - 1] - x[i - 2]) + noise[i -
1] * std
}
exp(x)
}
<bytecode: 0x55c81aa53c00>
<environment: namespace:nfidd>We can use this function to simulate a differenced AR process:
R <- geometric_diff_ar(init = 1, noise = rnorm(100), std = 0.1, damp = 0.1)
data <- tibble(t = seq_along(R), R = R)
ggplot(data, aes(x = t, y = R)) +
geom_line() +
labs(title = "Simulated data from an exponentiated AR(1) model with differencing",
x = "Time",
y = "R")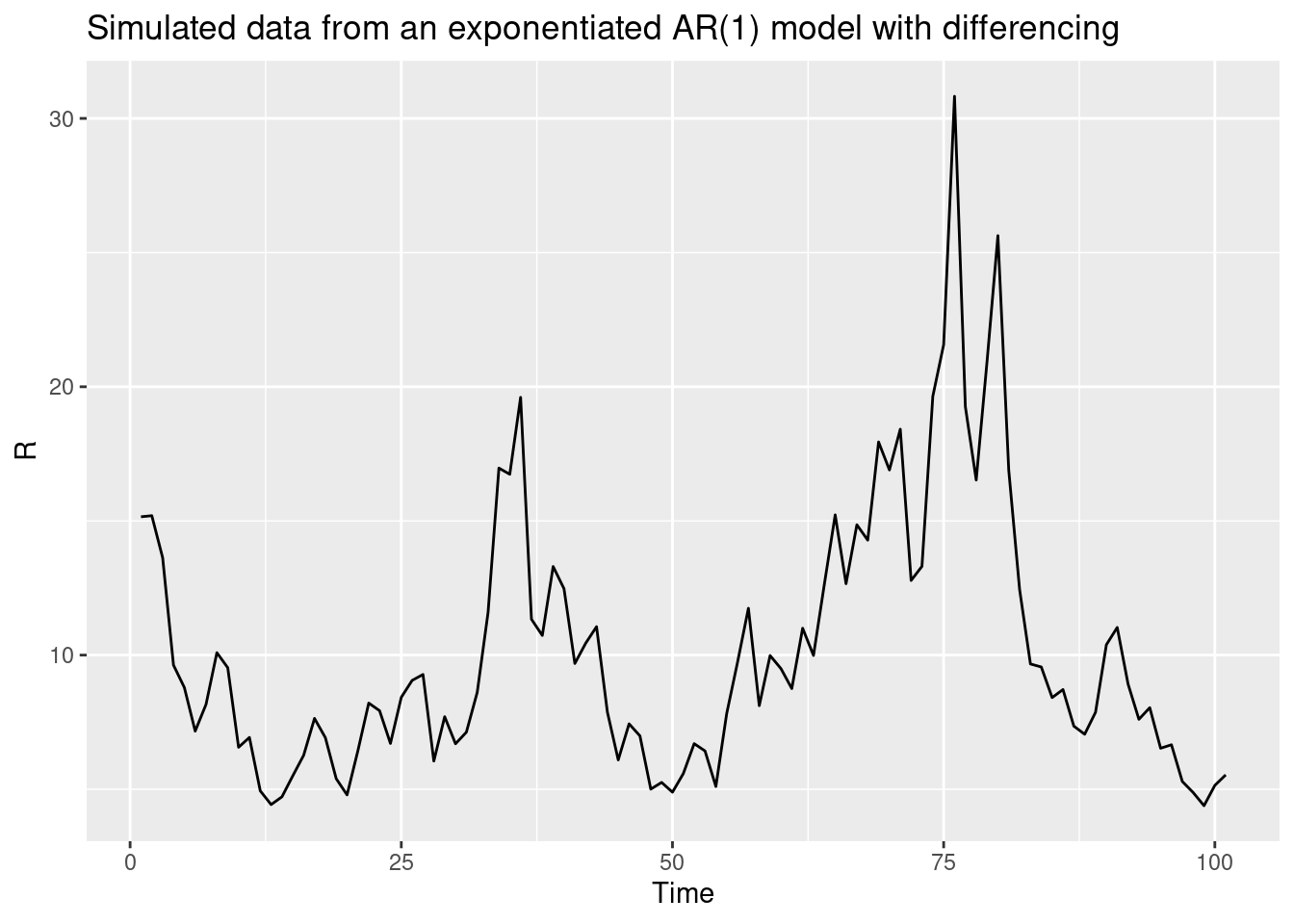
We’ve coded up a model that uses this differenced AR process as a stan model in stan/statistical-r.stan. See stan/functions/geometic_diff_ar.stan for the function which calculates the reproduction number. Lets load the model:
stat_mod <- nfidd_cmdstan_model("statistical-r")
stat_modfunctions {
#include "functions/convolve_with_delay.stan"
#include "functions/renewal.stan"
#include "functions/geometric_diff_ar.stan"
}
data {
int n; // number of days
int I0; // number initially infected
array[n] int obs; // observed symptom onsets
int gen_time_max; // maximum generation time
array[gen_time_max] real gen_time_pmf; // pmf of generation time distribution
int<lower = 1> ip_max; // max incubation period
array[ip_max + 1] real ip_pmf;
int h; // number of days to forecast
}
transformed data {
int m = n + h;
}
parameters {
real init_R; // initial reproduction number
array[m-1] real rw_noise; // random walk noise
real<lower = 0> rw_sd; // random walk standard deviation
real<lower = 0, upper = 1> damp; // damping
}
transformed parameters {
array[m] real R = geometric_diff_ar(init_R, rw_noise, rw_sd, damp);
array[m] real <upper = 1e5> infections = renewal(I0, R, gen_time_pmf);
array[m] real onsets = convolve_with_delay(infections, ip_pmf);
}
model {
// priors
init_R ~ normal(1, 0.5);
rw_noise ~ std_normal();
rw_sd ~ normal(0, 0.01) T[0,];
damp ~ normal(1, 0.05) T[0, 1];
obs ~ poisson(onsets[1:n]);
}
generated quantities {
array[h] real forecast;
if (h > 0) {
for (i in 1:h) {
forecast[i] = poisson_rng(onsets[n + i]);
}
}
}Forecasting with the mechanistic and statistical models
We will now use the mechanistic and statistical models to forecast the number of cases in the future using data simulated in the same way as we did in the forecasting concepts session. We will first load in the data and filter for a forecast origin date.
gen_time_pmf <- make_gen_time_pmf()
ip_pmf <- make_ip_pmf()
onset_df <- simulate_onsets(
make_daily_infections(infection_times), ip_pmf
)
onset_df# A tibble: 142 × 3
day onsets infections
<dbl> <int> <int>
1 1 0 0
2 2 0 1
3 3 0 0
4 4 0 2
5 5 0 1
6 6 1 1
7 7 0 1
8 8 0 3
9 9 2 0
10 10 1 0
# ℹ 132 more rows# we'll make a forecast on day non day 41, pretending we haven't seen the later
# data
cutoff <- 41
filtered_onset_df <- onset_df |>
filter(day <= cutoff)We will now fit the more mechanistic model to the data.
horizon <- 28
data <- list(
n = nrow(filtered_onset_df),
I0 = 1,
obs = filtered_onset_df$onsets,
gen_time_max = length(gen_time_pmf),
gen_time_pmf = gen_time_pmf,
ip_max = length(ip_pmf) - 1,
ip_pmf = ip_pmf,
h = horizon, # Here we set the number of days to forecast into the future
N_prior = c(10000, 2000) # the prior for the population size
)
mech_forecast_fit <- nfidd_sample(mech_mod, data = data)mech_forecast_fit variable mean median sd mad q5 q95 rhat ess_bulk
lp__ 50.18 50.48 0.98 0.68 48.20 51.09 1.00 950
R 1.47 1.47 0.02 0.02 1.44 1.50 1.00 1436
N 10060.30 10016.98 1956.68 1931.09 6816.88 13227.61 1.00 1244
infections[1] 0.10 0.10 0.00 0.00 0.10 0.10 1.00 1436
infections[2] 0.27 0.27 0.00 0.00 0.26 0.27 1.00 1436
infections[3] 0.37 0.37 0.00 0.00 0.36 0.38 1.00 1436
infections[4] 0.42 0.42 0.01 0.01 0.41 0.43 1.00 1437
infections[5] 0.46 0.46 0.01 0.01 0.44 0.47 1.00 1436
infections[6] 0.50 0.50 0.01 0.01 0.48 0.52 1.00 1437
infections[7] 0.56 0.56 0.01 0.01 0.53 0.58 1.00 1437
ess_tail
1348
917
1095
917
917
917
917
917
917
917
# showing 10 of 169 rows (change via 'max_rows' argument or 'cmdstanr_max_rows' option)We will now fit the more statistical model to the data.
data <- list(
n = nrow(filtered_onset_df),
I0 = 1,
obs = filtered_onset_df$onsets,
gen_time_max = length(gen_time_pmf),
gen_time_pmf = gen_time_pmf,
ip_max = length(ip_pmf) - 1,
ip_pmf = ip_pmf,
h = horizon # Here we set the number of days to forecast into the future
)
stat_forecast_fit <- nfidd_sample(
stat_mod, data = data,
# again set the initial values to make fitting more numerically stable
init = \() list(init_R = 1, rw_sd = 0.01)
)Finally, we can extract the forecasts from the models and plot them.
mech_forecast <- mech_forecast_fit |>
gather_draws(forecast[day]) |>
ungroup() |>
mutate(day = day + cutoff)
stat_forecast <- stat_forecast_fit |>
gather_draws(forecast[day]) |>
ungroup() |>
mutate(day = day + cutoff)
forecast <- bind_rows(
mutate(mech_forecast, model = "more mechanistic"),
mutate(stat_forecast, model = "more statistical")
) |>
ungroup()
target_onsets <- onset_df |>
filter(day > cutoff) |>
filter(day <= cutoff + horizon)forecast |>
filter(.draw %in% sample(.draw, 100)) |>
ggplot(aes(x = day)) +
geom_line(
alpha = 0.1,
aes(y = .value, group = interaction(.draw, model), colour = model)
) +
geom_point(data = target_onsets, aes(x = day, y = onsets), color = "black") +
guides(colour = guide_legend(override.aes = list(alpha = 1))) +
lims(y = c(0, 500))Warning: Removed 38 rows containing missing values or values outside the scale range
(`geom_line()`).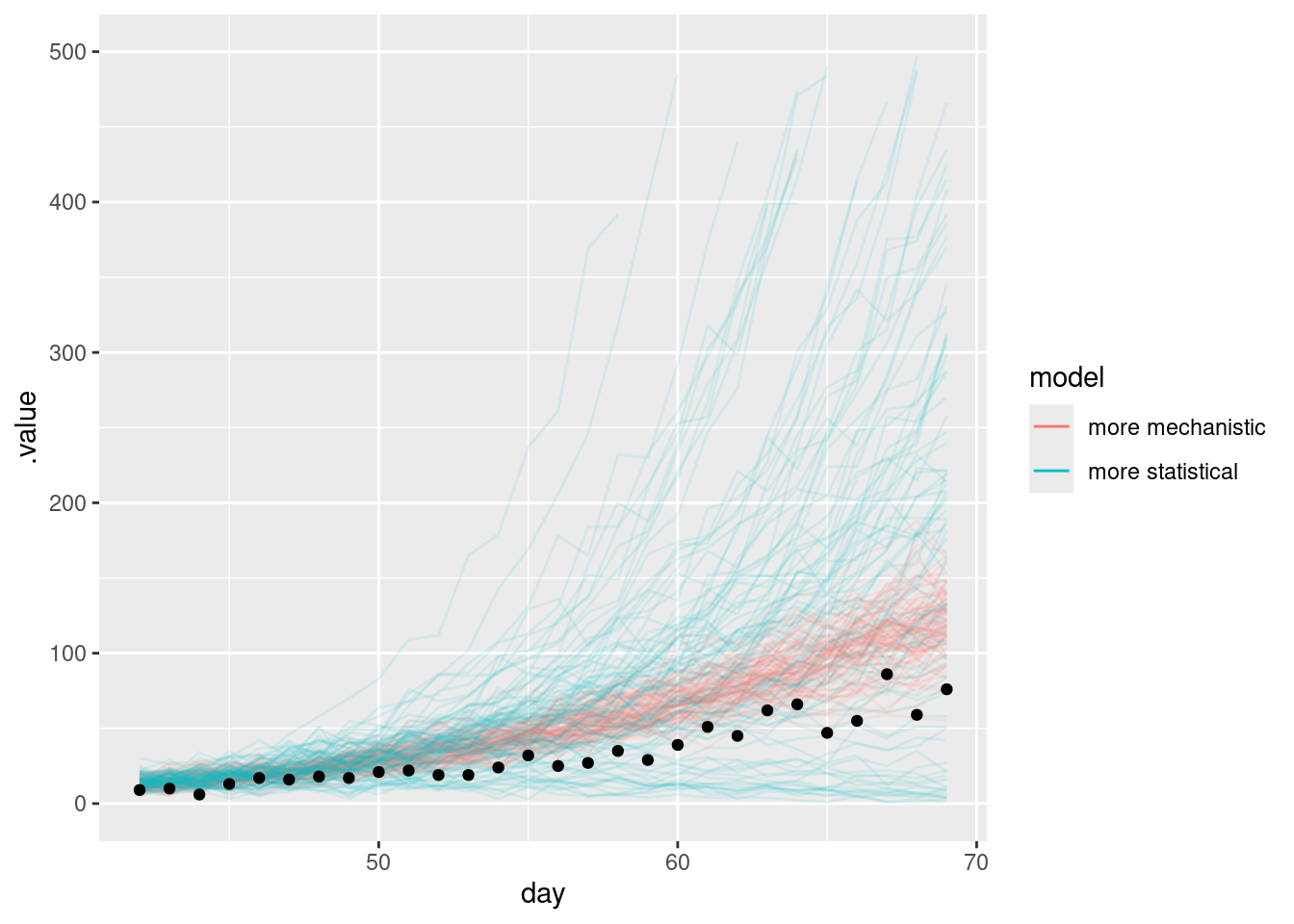
and on the log scale
forecast |>
filter(.draw %in% sample(.draw, 100)) |>
ggplot(aes(x = day)) +
geom_line(
alpha = 0.1,
aes(y = .value, group = interaction(.draw, model), colour = model)
) +
geom_point(data = target_onsets, aes(x = day, y = onsets), color = "black") +
scale_y_log10() +
guides(colour = guide_legend(override.aes = list(alpha = 1)))Warning in scale_y_log10(): log-10 transformation introduced infinite values.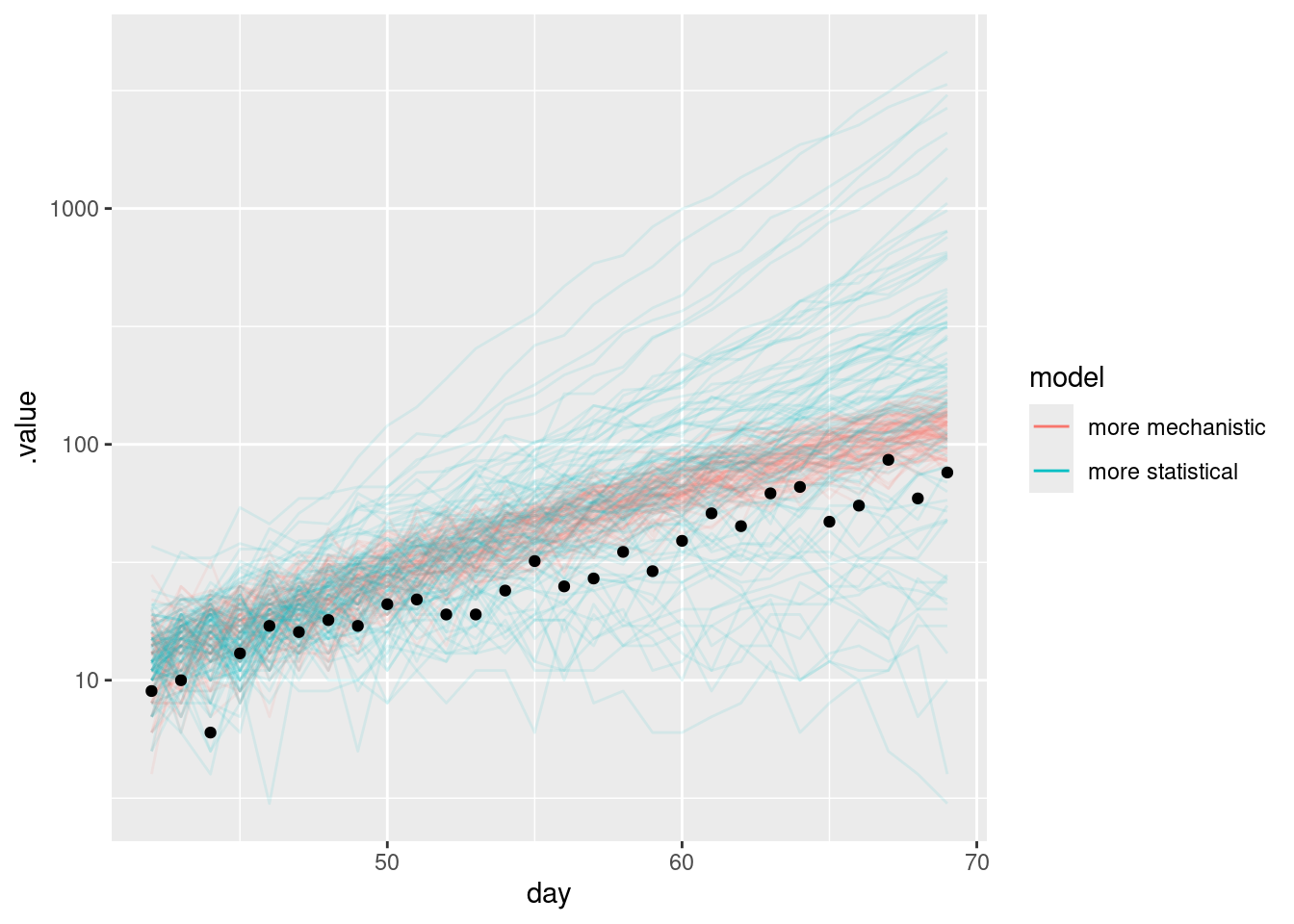
TipTake 2 minutes
What do you notice about the forecasts from the more mechanistic and more statistical models?
NoteSolution
- The more mechanistic model captures the trend in the data very well.
- The more statistical model produces some very large forecasts but also has significant probability mass on a a more rapid reduction that ultimately observed.
- Neither model simply extend the trend in the way the random walk model did in the forecasting concepts session.
Note
As these models are still renewal processes we can still plot the time-varying reproduction number which can be a helpful way of reasoning about how the models are performing.
stat_forecast_fit |>
gather_draws(R[day]) |>
ungroup() |>
filter(.draw %in% sample(.draw, 100)) |>
ggplot(aes(y = .value, x = day)) +
geom_hline(yintercept = 1, linetype = "dashed") +
geom_line(aes(group = .draw), alpha = 0.1)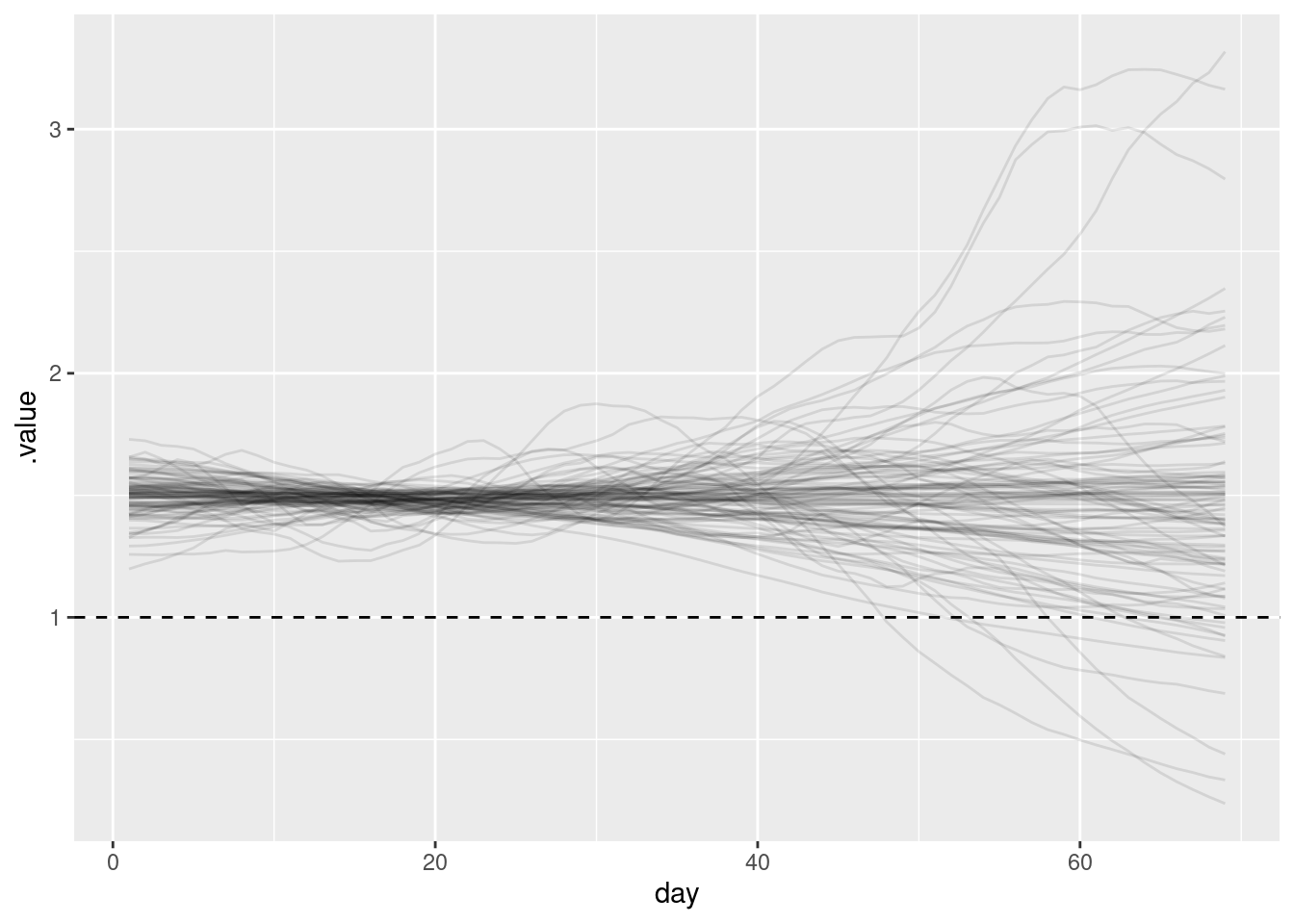
Evaluating forecasts from our models
As in the forecast evaluation session, we have fit these models to a range of forecast dates so you don’t have to wait for the models to fit. We will now evaluate the forecasts from the mechanistic and statistical models.
data(rw_forecasts, stat_forecasts, mech_forecasts)
forecasts <- bind_rows(
rw_forecasts,
mutate(stat_forecasts, model = "More statistical"),
mutate(mech_forecasts, model = "More mechanistic")
)
TipHow did we estimate these forecasts?
We generated these forecasts using the code in data-raw/generate-example-forecasts.r which uses the same approach we just took for a single forecast date but generalises it to many forecast dates.
Some important things to note about these forecasts:
- We used a 14 day forecast horizon.
- Each forecast used all the data up to the forecast date.
- We generated 1000 posterior samples for each forecast.
- We started forecasting 3 weeks into the outbreak and then forecast every 7 days until the end of the data (excluding the last 14 days to allow a full forecast).
- We use the same simulated outbreak data:
head(onset_df)# A tibble: 6 × 3
day onsets infections
<dbl> <int> <int>
1 1 0 0
2 2 0 1
3 3 0 0
4 4 0 2
5 5 0 1
6 6 1 1Visualising your forecast
forecasts |>
filter(.draw %in% sample(.draw, 100)) |>
ggplot(aes(x = day)) +
geom_line(aes(y = .value, group = interaction(.draw, origin_day), col = origin_day), alpha = 0.1) +
geom_point(data = onset_df |>
filter(day >= 21),
aes(x = day, y = onsets), color = "black") +
scale_color_binned(type = "viridis") +
facet_wrap(~model) +
lims(y = c(0, 500))Warning: Removed 80 rows containing missing values or values outside the scale range
(`geom_line()`).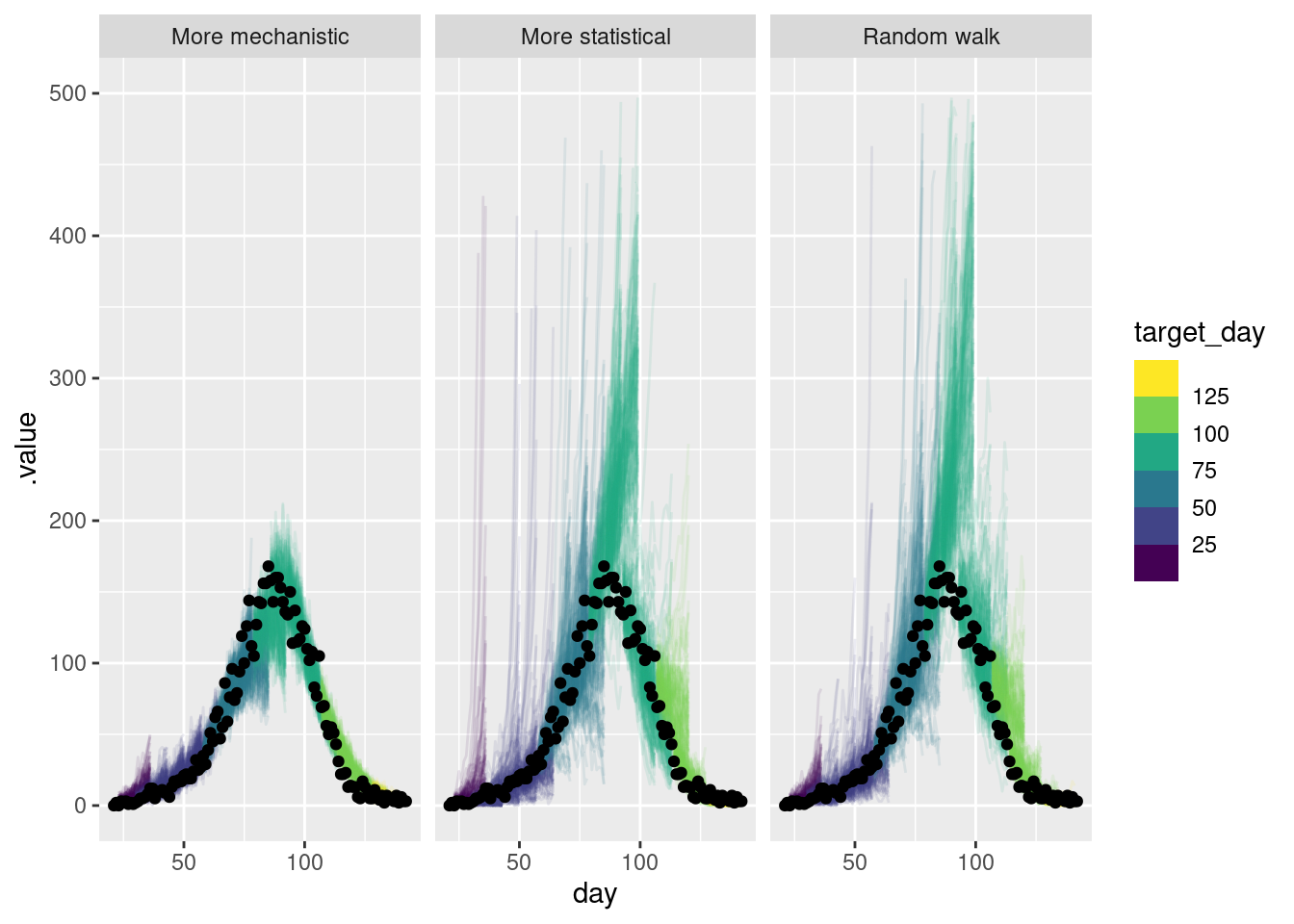
As for the single forecast it is helpful to also plot the forecast on the log scale.
forecasts |>
filter(.draw %in% sample(.draw, 100)) |>
ggplot(aes(x = day)) +
geom_line(
aes(y = .value, group = interaction(.draw, origin_day), col = origin_day),
alpha = 0.1
) +
geom_point(data = onset_df, aes(x = day, y = onsets), color = "black") +
scale_y_log10(limits = c(NA, 500)) +
scale_color_binned(type = "viridis") +
facet_wrap(~model)Warning in scale_y_log10(limits = c(NA, 500)): log-10 transformation introduced infinite values.
log-10 transformation introduced infinite values.Warning: Removed 75 rows containing missing values or values outside the scale range
(`geom_line()`).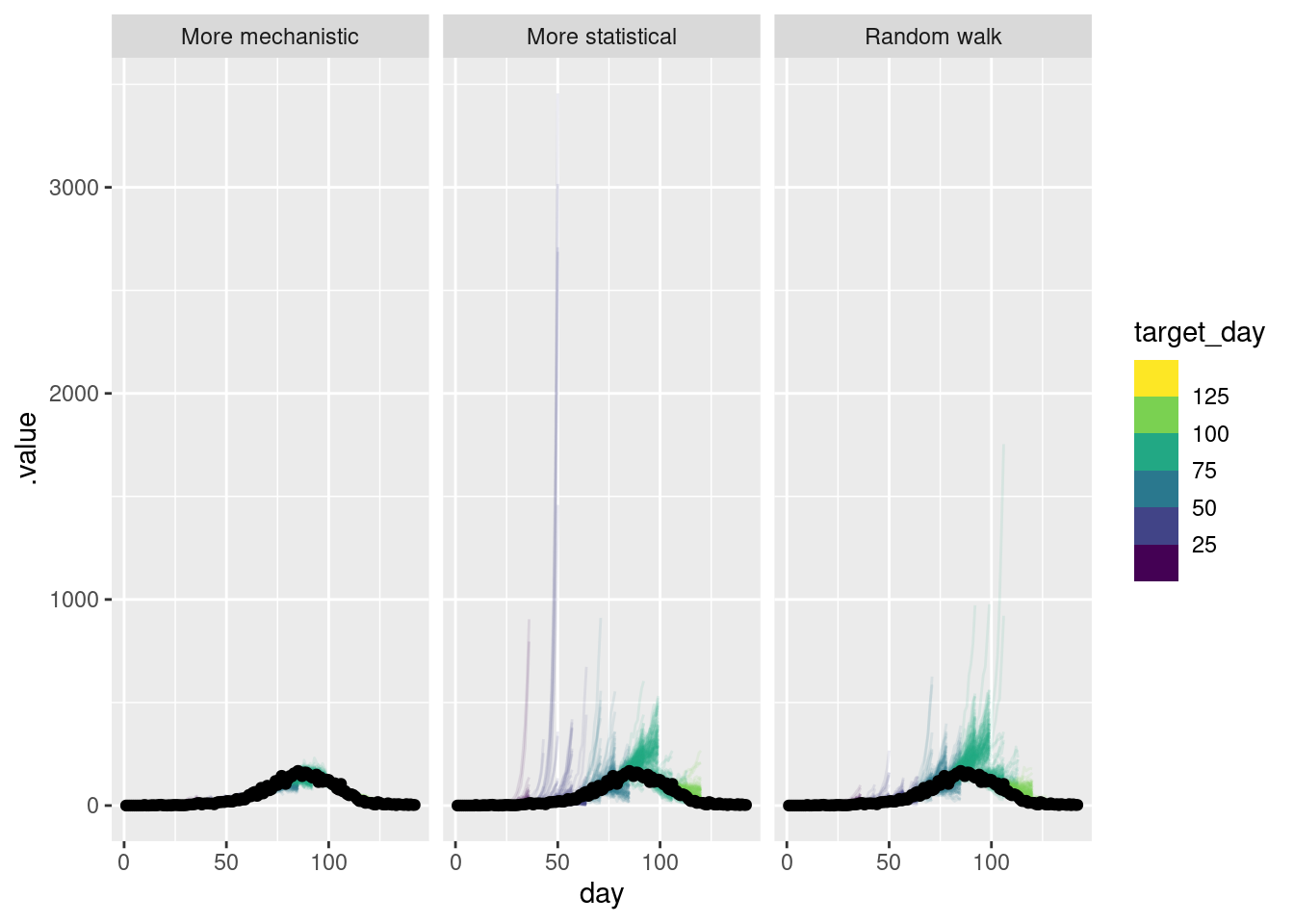
TipTake 5 minutes
How do these forecasts compare? Which do you prefer?
NoteSolution
How do these forecasts compare?
- The more mechanistic model captures the downturn in the data very well.
- Past the peak all models were comparable.
- The more statistical model captures the downturn faster than the random walk but less fast than the more mechanistic mode.
- The more statistical model sporadically predicts a more rapidly growing outbreak than occurred early on.
- The more statistical model is more uncertain than the mechanistic model but less uncertain than the random walk.
Which do you prefer?
- The more mechanistic model seems to be the best at capturing the downturn in the data and the uncertainty in the forecasts seems reasonable.
- If we weren’t confident in the effective susceptible population the AR model might be preferable.
Scoring your forecast
sc_forecasts <- forecasts |>
left_join(onset_df, by = "day") |>
filter(!is.na(.value)) |>
as_forecast_sample(
forecast_unit = c(
"origin_day", "horizon", "model"
),
observed = "onsets",
predicted = ".value",
sample_id = ".draw"
)
sc_forecastsForecast type: sampleForecast unit:origin_day, horizon, and model
sample_id predicted observed origin_day horizon model
<int> <num> <int> <num> <int> <char>
1: 1 1 1 22 1 Random walk
2: 2 1 1 22 1 Random walk
3: 3 2 1 22 1 Random walk
4: 4 2 1 22 1 Random walk
5: 5 4 1 22 1 Random walk
---
671996: 996 3 4 127 14 More mechanistic
671997: 997 5 4 127 14 More mechanistic
671998: 998 4 4 127 14 More mechanistic
671999: 999 2 4 127 14 More mechanistic
672000: 1000 0 4 127 14 More mechanisticEverything seems to be in order. We can now use the scoringutils package to calculate some metrics as we did in the forecasting evaluation session.
sc_scores <- sc_forecasts |>
score()Warning: Predictions appear to be integer-valued.
! The log score uses kernel density estimation, which may not be appropriate
for integer-valued forecasts.
ℹ See the scoringRules package for alternatives for discrete probability
distributions.sc_scores origin_day horizon model bias dss crps
<num> <int> <char> <num> <num> <num>
1: 22 1 Random walk 0.814 2.935661 1.447707
2: 22 2 Random walk 0.571 2.363184 0.999274
3: 22 3 Random walk 0.965 4.747737 2.989352
4: 22 4 Random walk 0.705 3.303900 1.701816
5: 22 5 Random walk 0.326 2.745704 0.960691
---
668: 127 10 More mechanistic 0.459 1.908066 0.758191
669: 127 11 More mechanistic 0.895 3.621946 1.909339
670: 127 12 More mechanistic 0.601 2.066790 0.917790
671: 127 13 More mechanistic -0.619 1.999204 1.017762
672: 127 14 More mechanistic -0.444 1.460549 0.703107
overprediction underprediction dispersion log_score mad ae_median
<num> <num> <num> <num> <num> <num>
1: 0.964 0.000 0.483707 2.127255 1.4826 2
2: 0.454 0.000 0.545274 1.925872 2.9652 2
3: 2.404 0.000 0.585352 3.314634 2.9652 4
4: 0.978 0.000 0.723816 2.292928 2.9652 3
5: 0.194 0.000 0.766691 2.119290 2.9652 1
---
668: 0.300 0.000 0.458191 1.823353 1.4826 1
669: 1.470 0.000 0.439339 2.526072 1.4826 3
670: 0.452 0.000 0.465790 1.758339 1.4826 2
671: 0.000 0.600 0.417762 1.987282 1.4826 2
672: 0.000 0.284 0.419107 1.750167 1.4826 1
se_mean
<num>
1: 6.466849
2: 3.625216
3: 19.820304
4: 10.010896
5: 3.164841
---
668: 1.907161
669: 8.779369
670: 2.849344
671: 2.669956
672: 1.050625
NoteLearning more about the output of
score()
See the documentation for ?get_metrics.forecast_sample for information on the default sample metrics.
At a glance
Let’s summarise the scores by model first.
sc_scores |>
summarise_scores(by = "model") model bias dss crps overprediction underprediction
<char> <num> <num> <num> <num> <num>
1: Random walk 0.1912857 6.483105 14.263870 8.859304 0.9962054
2: More statistical 0.0183750 6.716926 12.505070 6.547500 1.7254107
3: More mechanistic 0.2237991 5.806150 7.013138 2.422223 2.6138036
dispersion log_score mad ae_median se_mean
<num> <num> <num> <num> <num>
1: 4.408361 4.087915 18.343866 19.209821 1643.5816
2: 4.232159 4.073838 17.235225 17.154018 1195.1379
3: 1.977111 3.809068 8.389266 9.774554 207.2815
TipTake 2 minutes
Before we look in detail at the scores, what do you think the scores are telling you? Which model do you think is best?
Continuous ranked probability score
As in the forecast evaluation session, we will start by looking at the CRPS by horizon and forecast date.
TipReminder: Key things to note about the CRPS
- Small values are better
- When scoring absolute values (e.g. number of cases) it can be difficult to compare forecasts across scales (i.e., when case numbers are different, for example between locations or at different times).
First by forecast horizon.
sc_scores |>
summarise_scores(by = c("model", "horizon")) |>
ggplot(aes(x = horizon, y = crps, col = model)) +
geom_point()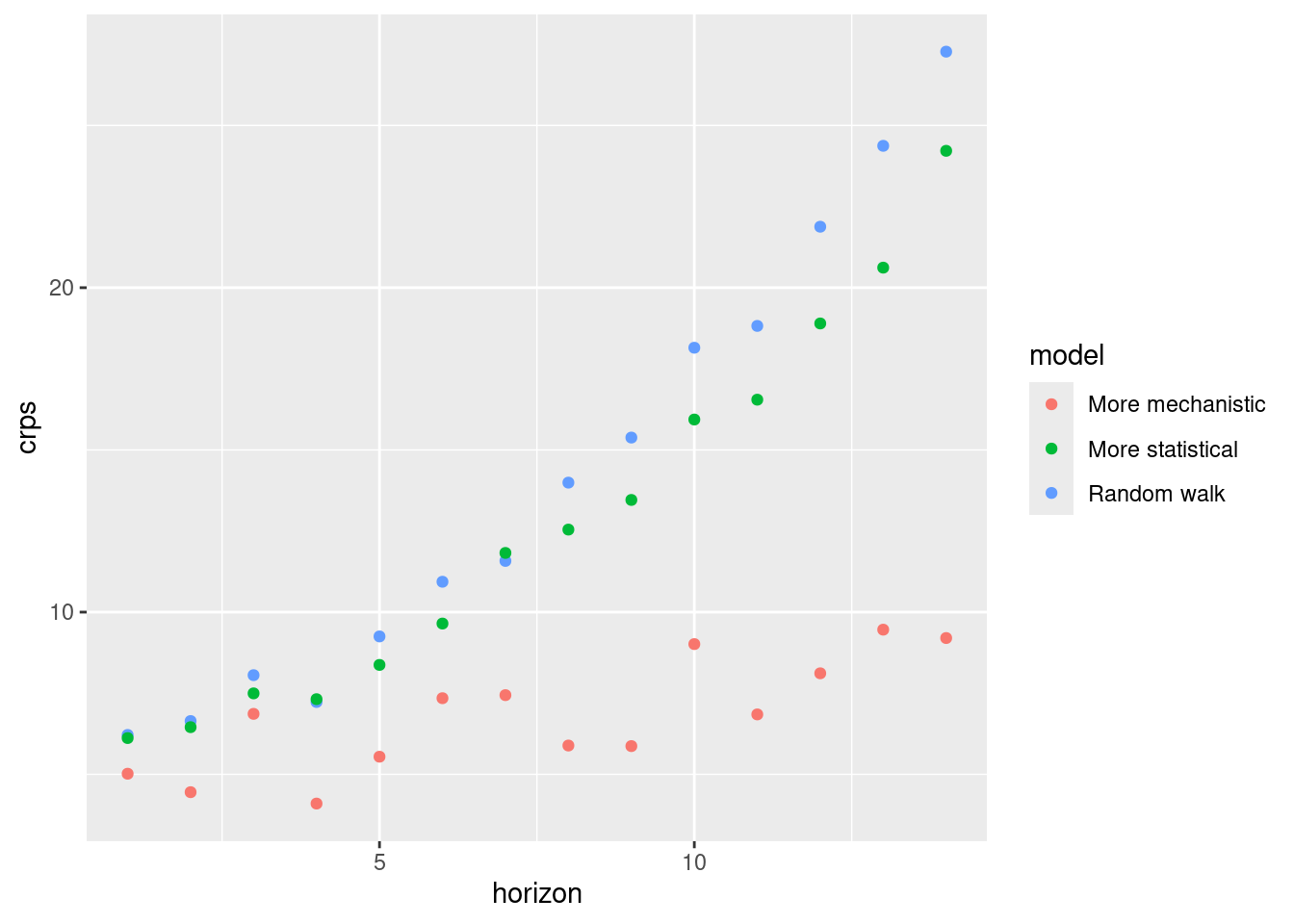
and across different forecast dates
sc_scores |>
summarise_scores(by = c("origin_day", "model")) |>
ggplot(aes(x = origin_day, y = crps, col = model)) +
geom_point()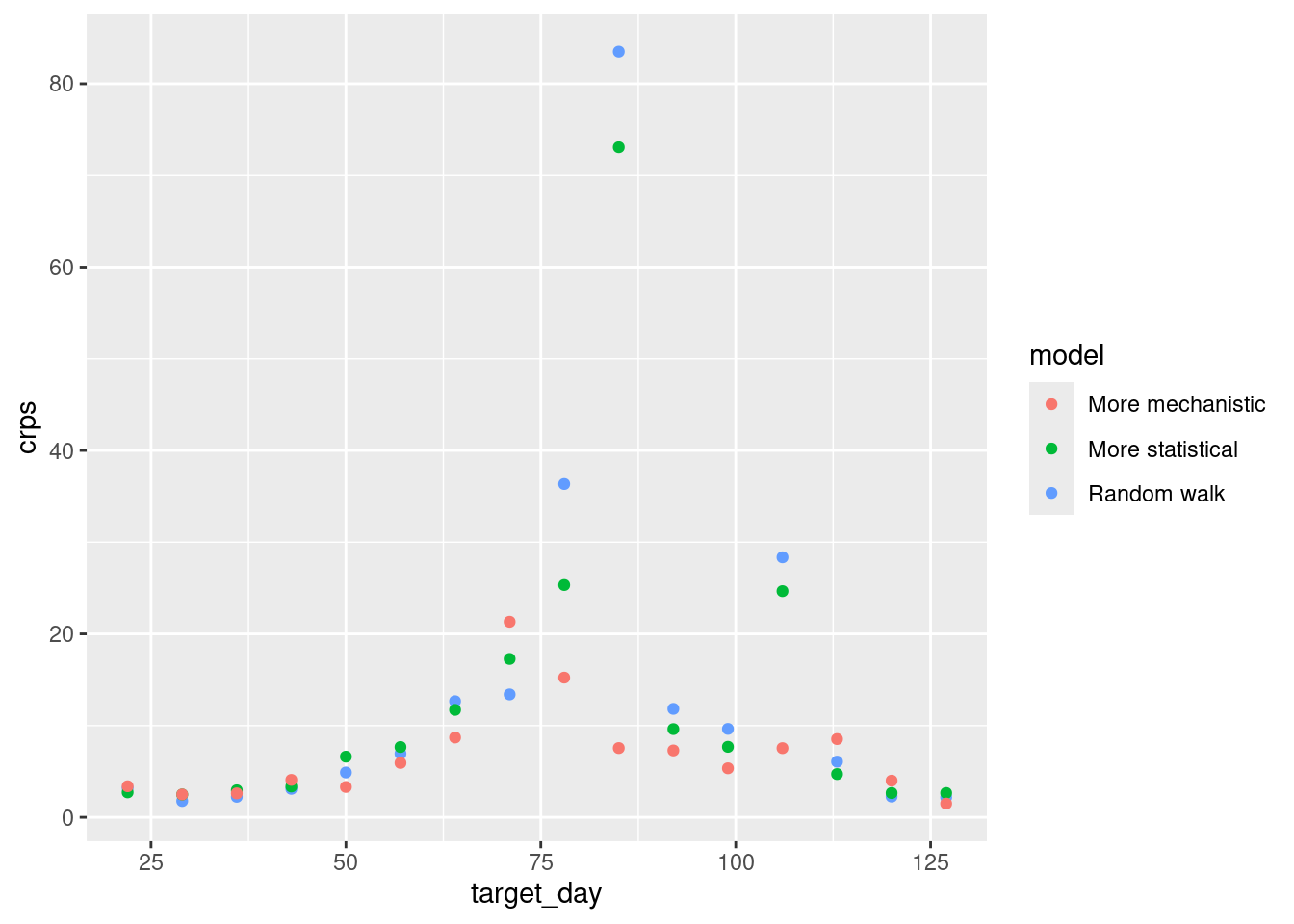
TipTake 5 minutes
How do the CRPS values change based on forecast date? How do the CRPS values change with forecast horizon?
NoteSolution
How do the CRPS values change based on forecast horizon?
- All models have increasing CRPS with forecast horizon.
- The more mechanistic model has the lowest CRPS at all forecast horizon.
- The more stastical model starts to outperform the random walk model at longer time horizons.
How do the CRPS values change with forecast date?
- The more statistical model does particularly poorly around the peak of the outbreak but outperforms the random walk model.
- The more mechanistic model does particularly well around the peak of the outbreak versus all other models
- The more statistical model starts to outperform the other models towards the end of the outbreak.
PIT histograms
TipReminder: Interpreting the PIT histogram
- Ideally PIT histograms should be uniform.
- If is a U shape then the model is overconfident and if it is an inverted U shape then the model is underconfident.
- If it is skewed then the model is biased towards the direction of the skew.
Let’s first look at the overall PIT histogram.
sc_forecasts |>
get_pit_histogram(by = "model") |>
ggplot(aes(x = mid, y = density)) +
geom_col() +
facet_wrap(~model) +
labs(x = "Predicted quantiles")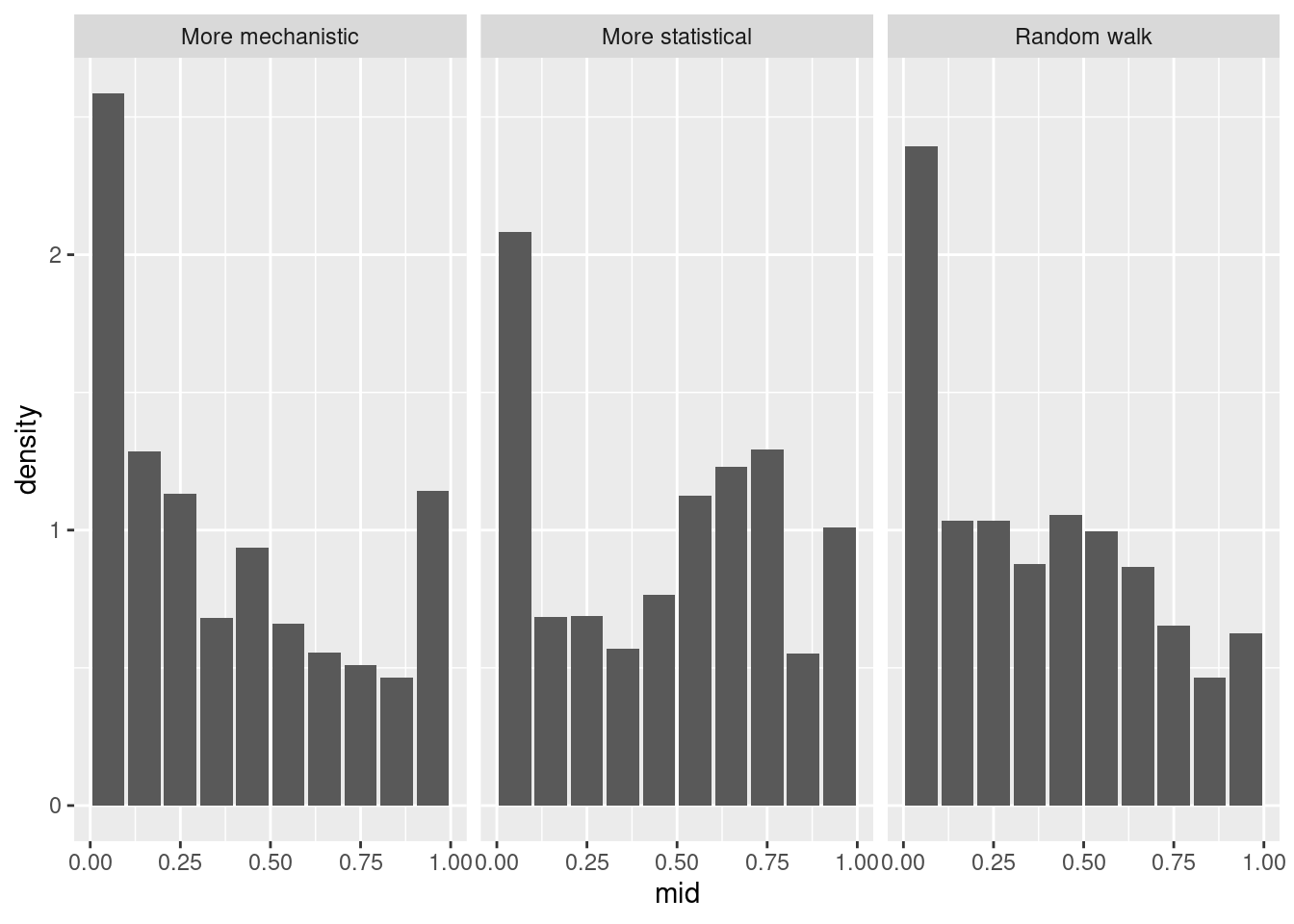
As before let’s look at the PIT histogram by forecast horizon (to save space we will group horizons)
sc_forecasts |>
mutate(group_horizon = case_when(
horizon <= 3 ~ "1-3",
horizon <= 7 ~ "4-7",
horizon <= 14 ~ "8-14"
)) |>
get_pit_histogram(by = c("model", "group_horizon")) |>
ggplot(aes(x = mid, y = density)) +
geom_col() +
facet_grid(vars(model), vars(group_horizon)) +
labs(x = "Predicted quantiles")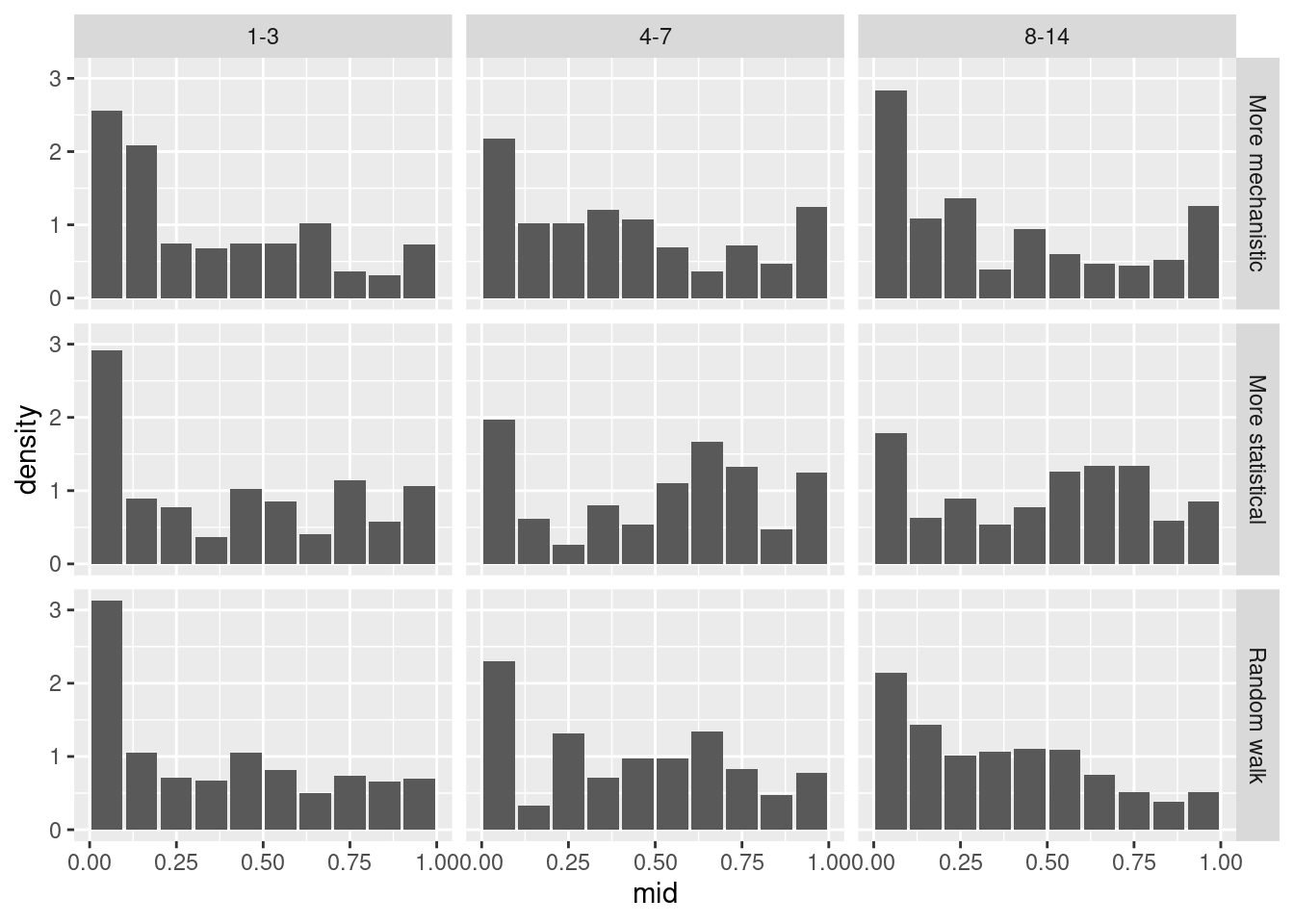
and then for different forecast dates.
sc_forecasts |>
get_pit_histogram(by = c("model", "origin_day")) |>
ggplot(aes(x = mid, y = density)) +
geom_col() +
facet_grid(vars(model), vars(origin_day)) +
labs(x = "Predicted quantiles")
TipTake 5 minutes
What do you think of the PIT histograms?
NoteSolution
What do you think of the PIT histograms?
- The more mechanistic model is reasonably well calibrated but has a slight tendency to be overconfident.
- The random walk is biased towards overpredicting.
- The more statistical model is underconfident.
- Across horizons the more mechanistic model is only liable to underpredict at the longest horizons.
- The random walk model is initially relatively unbiased and well calibrated but becomes increasingly likely to overpredict as the horizon increases.
- The forecast date stratified PIT histograms are hard to interpret. We may need to find other ways to visualise bias and calibration at this level of stratification (see the
{scoringutils}documentation for some ideas).
Scoring on the log scale
Again as in the forecast evaluation session, we will also score the forecasts on the log scale.
log_sc_forecasts <- sc_forecasts |>
transform_forecasts(
fun = log_shift,
offset = 1,
append = FALSE
)
log_sc_scores <- log_sc_forecasts |>
score()
Tip
Reminder: For more on scoring on the log scale see Bosse et al. (2023) on scoring forecasts on transformed scales.
At a glance
log_sc_scores |>
summarise_scores(by = "model") model bias dss crps overprediction
<char> <num> <num> <num> <num>
1: Random walk 0.1912857 -0.2018501 0.2649167 0.13482094
2: More statistical 0.0183750 -0.2990324 0.2738192 0.09857831
3: More mechanistic 0.2237991 -0.6988882 0.2170715 0.14205786
underprediction dispersion log_score mad ae_median se_mean
<num> <num> <num> <num> <num> <num>
1: 0.04150453 0.08859122 0.6919976 0.3783451 0.3584795 0.2406567
2: 0.07384108 0.10139979 0.6854568 0.4240924 0.3727206 0.2553578
3: 0.02360587 0.05140782 0.4008548 0.2173315 0.2974642 0.1796232
TipTake 2 minutes
Before we look in detail at the scores, what do you think the scores are telling you? Which model do you think is best?
CRPS
log_sc_scores |>
summarise_scores(by = c("model", "horizon")) |>
ggplot(aes(x = horizon, y = crps, col = model)) +
geom_point()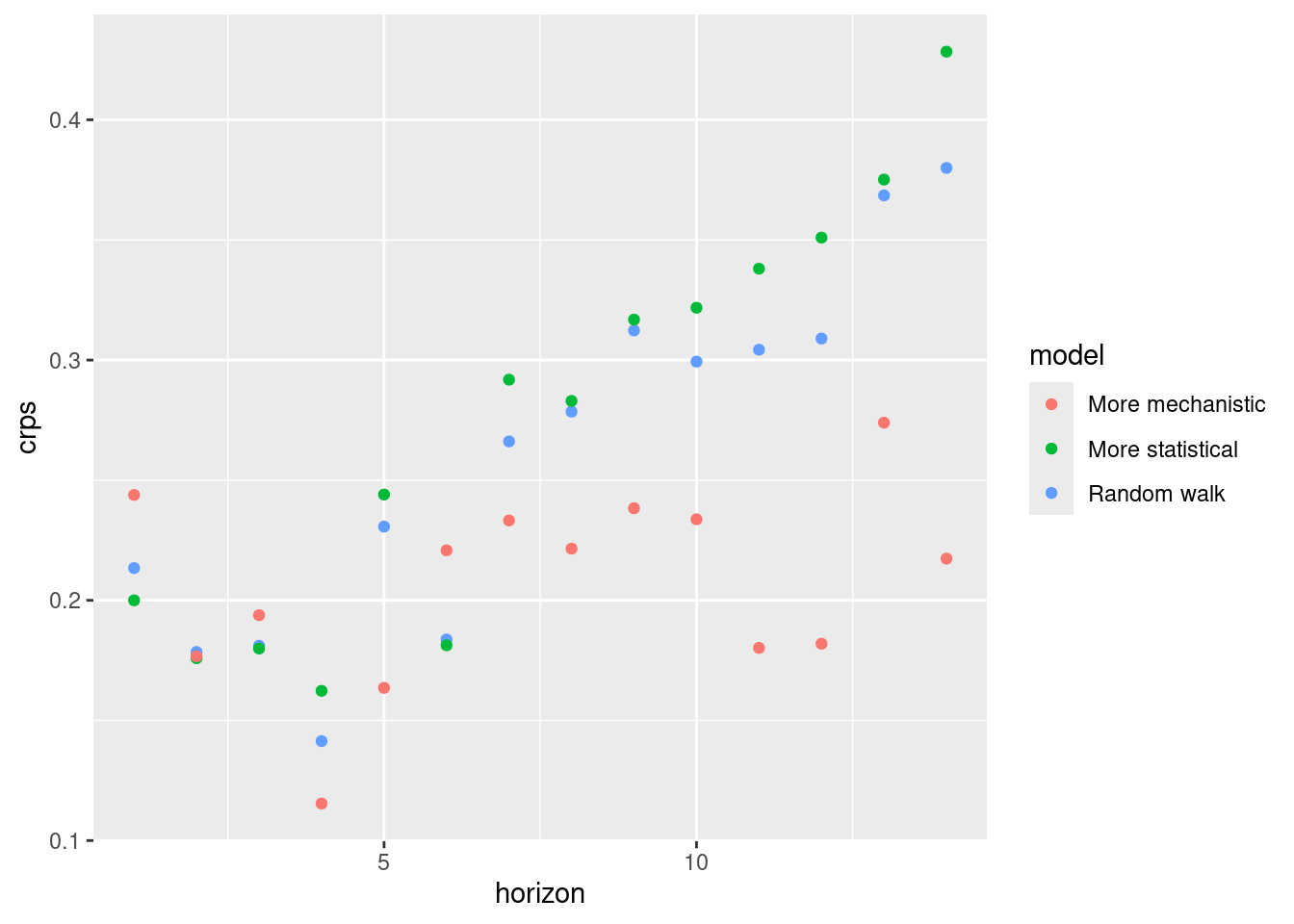
log_sc_scores |>
summarise_scores(by = c("origin_day", "model")) |>
ggplot(aes(x = origin_day, y = crps, col = model)) +
geom_point()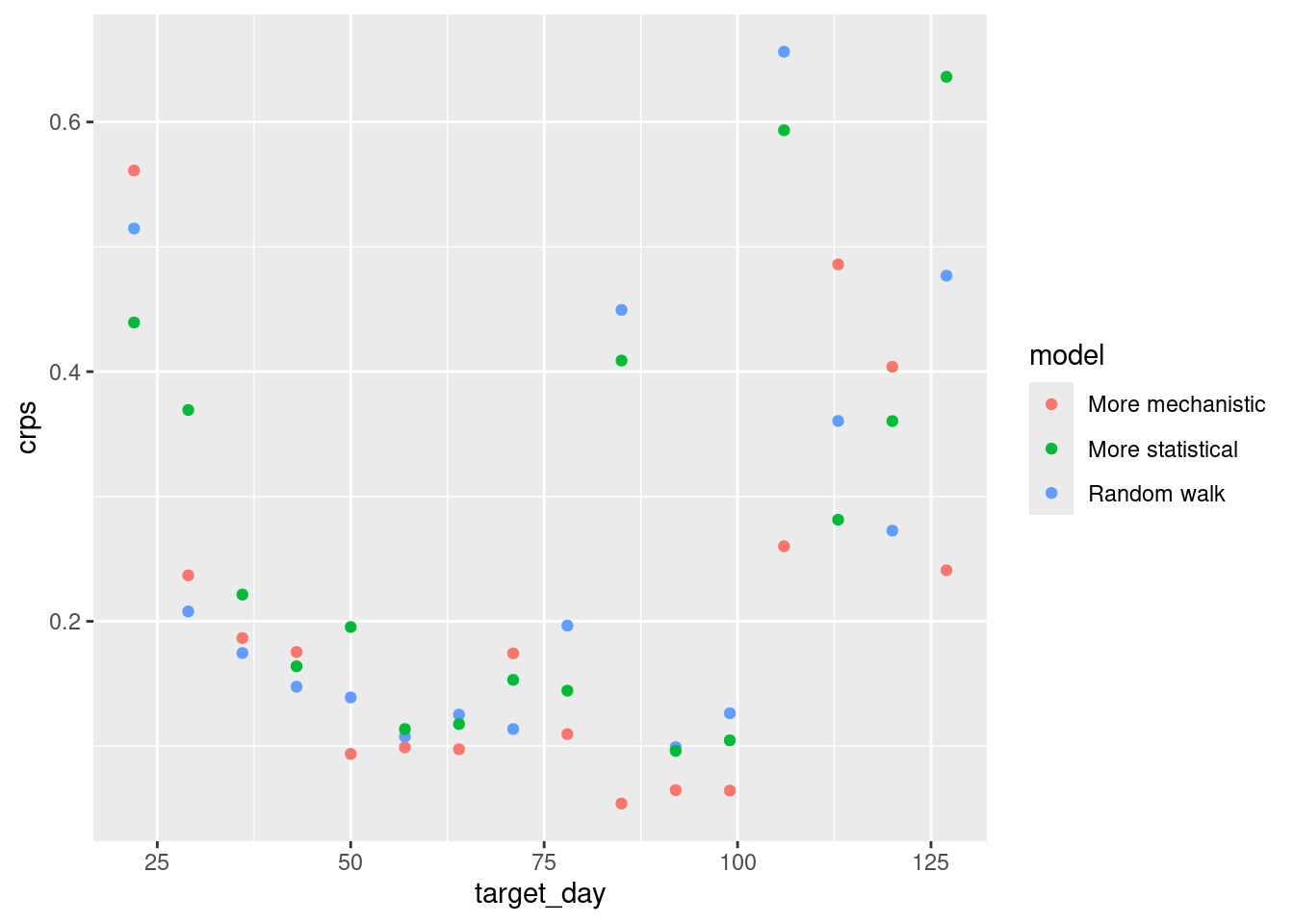
TipTake 5 minutes
How do the CRPS values on the log scale compare to the scores on the original scale?
NoteSolution
- The performance of the mechanistic model is more variable across forecast horizon than on the natural scale.
- On the log scale the by horizon performance of the random walk and more statistical mdoel is more comparable than on the log scale.
- The period of high incidence dominates the origin day stratified scores less on the log scale. We see that all models performed less well early and late on.
Going further
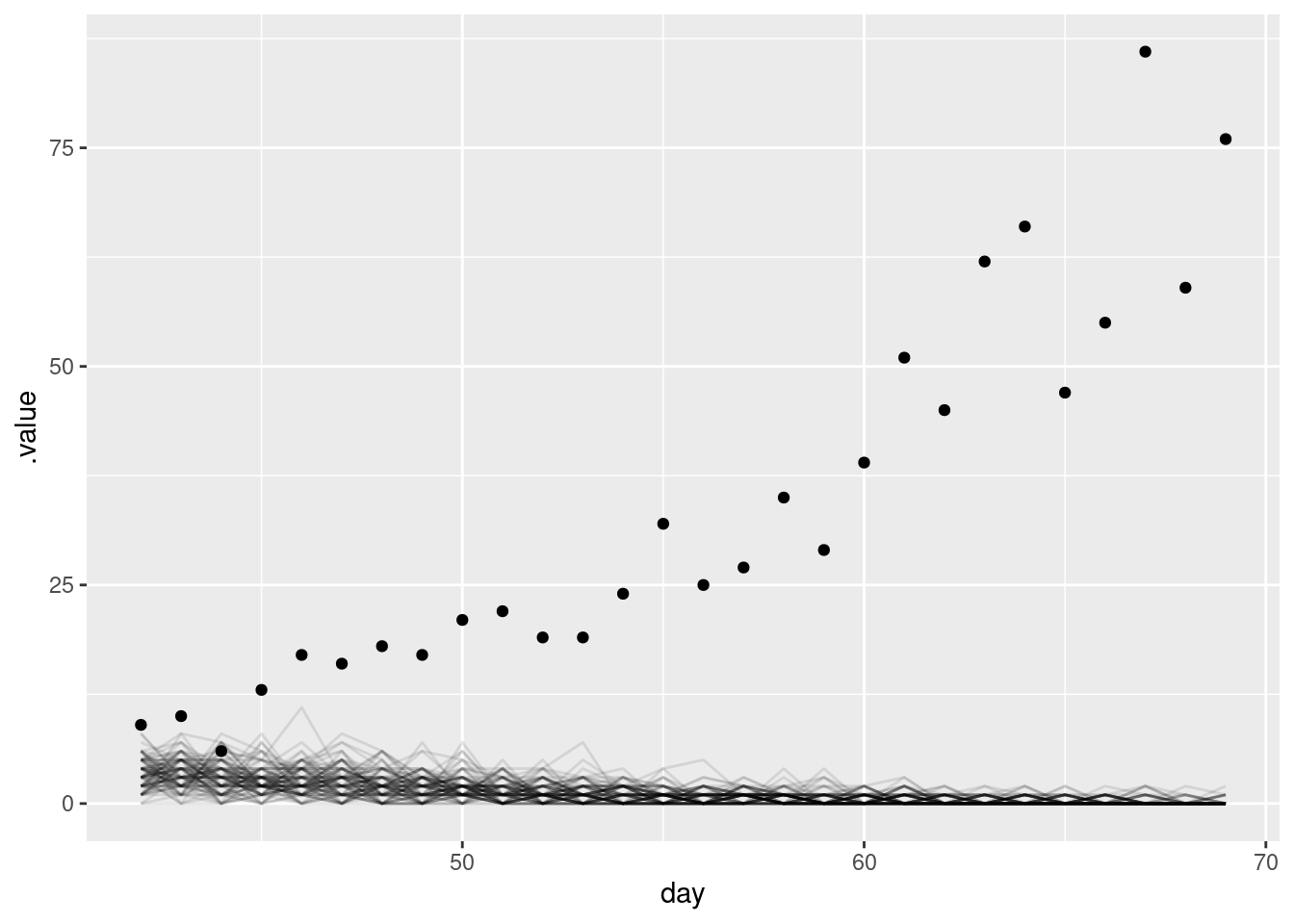
What happens when you are very wrong about the population size?
In the forecasts above we assumed that we knew the population size roughly. In practice, we may not. Refit the more mechanistic model with different priors for the population size and see how the forecasts change.
NoteSolution
data <- list(
n = nrow(filtered_onset_df),
I0 = 1,
obs = filtered_onset_df$onsets,
gen_time_max = length(gen_time_pmf),
gen_time_pmf = gen_time_pmf,
ip_max = length(ip_pmf) - 1,
ip_pmf = ip_pmf,
h = horizon, # Here we set the number of days to forecast into the future
N_prior = c(100, 20) # the prior for the population size
)
mech_forecast_fit_diff <- nfidd_sample(
mech_mod, data = data
)
mech_forecast_diff <- mech_forecast_fit_diff |>
gather_draws(forecast[day]) |>
ungroup() |>
mutate(day = day + cutoff)mech_forecast_diff |>
filter(.draw %in% sample(.draw, 100)) |>
ggplot(aes(y = .value, x = day)) +
geom_line(alpha = 0.1, aes(group = .draw)) +
geom_point(
data = target_onsets, aes(x = day, y = onsets),
color = "black"
)
Challenge
- We have only looked at three forecasting models here. There are many more models that could be used. For example, we could use a more complex mechanistic model which captures more of the underlying dynamics of the data generating process. We could also use a more complex statistical model which captures more of the underlying structure of the data.
- We could also combine the more mechanistic and more statistical models to create a hybrid model which captures the best of both worlds (maybe).
- We could also use a more complex scoring rule to evaluate the forecasts. For example, we could use a multivariate scoring rule which captures more of the structure of the data.
- Consider how forecasting approaches might differ in non-outbreak settings: What additional factors might you need to account for when applying these methods to routine surveillance data? Think about seasonal patterns, long-term trends, holiday effects, or other cyclical behaviours that might influence transmission dynamics and reporting patterns.
Methods in practice
- The statistical models we’ve discussed here represent just a subset of available forecasting approaches. For a comprehensive treatment of time series forecasting models, including ARIMA models as a generalisation of autoregressive approaches with additional features for differencing and moving averages, see Hyndman and Athanasopoulos (2021). These models offer a different workflow for thinking about forecasting. Whilst Bayesian approaches work forward from domain knowledge to specify data-generating processes, traditional time series methods work backward from observed patterns using standard toolkits (transformations, differencing, residual analysis) to achieve stationarity and improve predictions. Both approaches ultimately aim to capture the same underlying data-generating process but from different perspectives. Something to think about!
- Gaussian process models (as implemented in EpiNow2) provide another flexible approach that can generalise many of these statistical models depending on kernel choice.
Wrap up
- Review what you’ve learned in this session with the learning objectives
- Share your questions and thoughts
References
Bosse, Nikos I., Sam Abbott, Anne Cori, Edwin van Leeuwen, Johannes Bracher, and Sebastian Funk. 2023. “Scoring Epidemiological Forecasts on Transformed Scales.” PLOS Computational Biology 19 (8): e1011393. https://doi.org/10.1371/journal.pcbi.1011393.
Hyndman, Rob J, and George Athanasopoulos. 2021. Forecasting: Principles and Practice. 3rd ed. OTexts.